Proof of Reserve with Merkle tree
While RWA dApps currently use a centralized validator role for off-chain collateral verification, we can explore a more decentralized approach by increasing the number of validators. This would require a robust consensus mechanism among them. Additionally, given the cost-effectiveness of computations on the shared Ethereum virtual machine, we propose adopting a proof-of-reserve strategy. This approach allows validators to efficiently commit a large amount of collateral data using a single Merkle tree root.
We will begin with the Merkle tree data structure. There are various ways to implement this structure, but the key element is the use of a hash function (a one-way function).
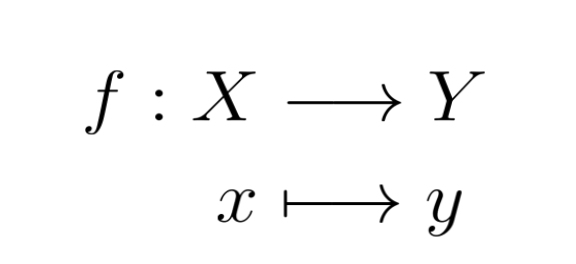
Hash functions are fundamental to modern data management, providing a means to efficiently transform information of any size into fixed-length strings. This transformation enhances the speed of data storage and retrieval. Additionally, hash functions contribute an important security feature: they generate a unique fingerprint for each data set, known as a hash value. This hash value is sensitive to changes; even a minor alteration in the data will result in a completely different hash value, thereby detecting any potential tampering.
Merkle trees utilize hash functions to maintain data integrity in distributed environments. In a Merkle tree, each leaf node contains the hash of a data block. For non-leaf nodes, their value is derived from the combined hash of their left and right child nodes. This process continues up the tree, with each parent node containing the hash of its children’s hashes. The root node, which holds the final hash, represents the entire tree’s fingerprint. Any modification to a single data block will propagate through the tree, altering all associated hashes up to the root. This allows for efficient data integrity verification: by comparing the root hash of a downloaded file with the original source’s published root hash, one can verify if the data remains unchanged.
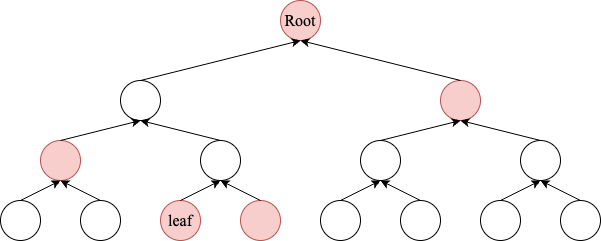
Verifying data in a Merkle tree is surprisingly straightforward. Think of it like a family tree, where the data you want to verify is a descendant (leaf node) and the root represents the ancestor. To confirm if the data belongs to the tree, follow these steps:
- Gather Cousin Hashes: Request the "cousin hashes" along the path from your data to the known root hash. These cousin hashes are the sibling nodes (nodes at the same level) of the nodes on your path.
- Combine and Climb: Begin with the hash of your data, which acts as a unique identifier. Combine it with each cousin hash you receive as you move up the tree, similar to piecing together a family history.
- Match the Root Hash: If the final hash obtained after combining all the cousin hashes matches the known root hash of the entire tree, then the data is confirmed to be part of the Merkle tree. It’s like finding a match with the family ancestor.
In the RWA scenario, validators only need to provide the consensus data at the root of the Merkle tree. This allows anyone to verify the metadata of all collaterals using just a proof obtained from a validator.